#Móvilgeddon: Hoy Google cambiará su algoritmo de búsqueda para favorecer a los contenidos móviles

El gigante tecnológico Google introducirá este martes un nuevo algoritmo de búsqueda para modificar las recomendaciones de sitios web en los móviles, de forma que tengan prioridad las páginas adaptadas para celulares.
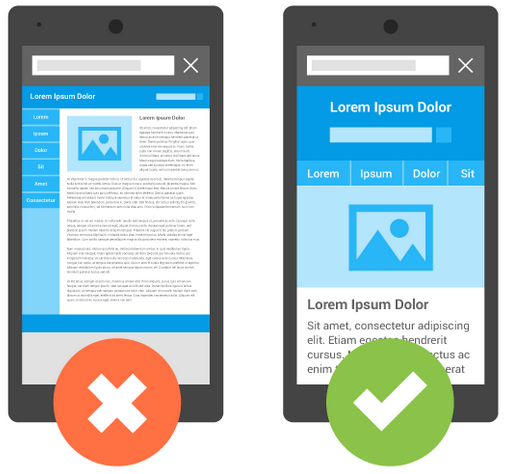
Los expertos en optimización de búsquedas para teléfonos celulares han bautizado el cambio con el nombre de «Móvilgeddon» y predicen que las compañías que no estén preparadas sufrirán mucho.
Una versión de prueba facilitada por Google muestra, por ejemplo, que páginas web de la Unión Europea (UE) no están diseñadas para funcionar bien en teléfonos móviles y contienen texto que es demasiado pequeño para resultar legible, vínculos que aparecen muy juntos y contenido más ancho que la pantalla.
La compañía tecnológica introdujo el año pasado una página de prueba para que los usuarios puedan ver si su sitio web está adaptado o no para los teléfonos móviles.
Puedes chequear tu sitio desde este enlace https://www.google.com/webmasters/tools/mobile-friendly/
Si te aparece algo como esto:

como cuando chequee a ventics.com

todo esta bien y puedes dormir tranquil@ , pero si te sale algo como esto:

Empieza a preocuparte, si no sabes que hacer puedes contactarme desde este enlace
Ing. Roberto Alemán
CLASES DE ALGORITMOS
Una forma de clasificar los algoritmos consiste en diferenciarlos por su metodología de diseño. A continuación se presenta una síntesis de las metodologías más comunes, aplicables cada una a diferentes clases de problemas:
Fuerza bruta: los algoritmos de fuerza bruta resuelven el problema con la estrategia más obvia de solución, que no siempre es la mejor según el número de operaciones que se requiere.
Divide and conquer (divide y reinarás): esta metodología divide las instancias del problema a resolver en instancias cada vez más pequeñas, usualmente en forma recursiva, hasta llegar a una instancia en que el problema es resoluble en forma trivial o con unas pocas instrucciones. Los algoritmos de búsqueda binaria son un ejemplo de la metodología divide and conquer.
Programación dinámica: cuando un problema presenta una subestructura óptima –o sea, cuando la solución óptima de un problema se obtiene a partir de las soluciones óptimas de sus subproblemas–, se encuentra la solución resolviendo primero los subproblemas más sencillos y luego utilizando esas subsoluciones para resolver problemas incrementalmente difíciles. Por ejemplo, si se tiene una serie de puntos (definidos por coordenadas x, y) que delimitan una región, y se necesita saber si otro punto se encuentra dentro o fuera de esa región, una forma de resolver el problema consiste en comenzar formando cuadrados con puntos contiguos, para luego formar figuras cada vez más grandes y, por cada figura, determinar si el punto está dentro o fuera de ella. En cada paso se aprovecha la información de los pasos anteriores, hasta que, al completar todos los puntos, se obtiene el resultado del problema.
Programación lineal: para resolver un problema utilizando programación lineal, se plantea una serie de inecuaciones y luego se busca maximizar (o minimizar) las variables, respetando las inecuaciones. Muchos problemas pueden plantearse en la forma de un conjunto de inecuaciones, para luego resolverlos utilizando un algoritmo genérico, como por ejemplo, el denominado método Simplex (en la sección de Servicios al lector se detallan sitios donde obtener más información sobre este método).
Búsqueda y enumeración: muchos problemas (como por ejemplo, un juego de ajedrez) pueden modelarse con grafos y resolverse a partir de un algoritmo de exploración del grafo. Tal algoritmo especificará las reglas para moverse en el grafo en busca de la solución al problema. Esta categoría incluye también algoritmos de backtracking (vuelta atrás), los cuales van ensayando distintos caminos con posibles soluciones
y vuelven atrás cuando no las encuentran. Por ejemplo, para encontrar la salida en un laberinto, cada vez que se llega al final de un camino se vuelve atrás hasta la última bifurcación, para probar con las distintas alternativas de esa bifurcación.
Algoritmos heurísticos: el propósito de estos algoritmos no es necesariamente encontrar una solución final al problema, sino encontrar una solución aproximada cuando el tiempo o los recursos necesarios para encontrar la solución perfecta son excesivos. Muchos sistemas antivirus utilizan métodos heurísticos para detectar conductas de programas que podrían estar actuando en forma maliciosa.
Algoritmos voraces: seleccionan la opción de solución (solución local) que tenga un costo menor en la etapa de solución en la que se encuentran, sin considerar si esa opción es parte de una solución óptima para el problema completo (solución global).
Google Penguin, un algoritmo renovado que quiere combatir el spam, a su manera..
Tras el lanzamiento del nuevo algoritmo bajo el nombre de Google Pingüino (Google Penguin) empiezan a llegar sus primeros efectos.
En una búsqueda constante de mejora de los resultados ofrecidos por Google, el equipo de trabajo del motor de búsqueda líder de Internet lanzaba el pasado 24 de abril una actualización de su formula secreta con la que posicionar websites y que en este caso está dirigida a penalizar aquellos sites con un exceso de optimización SEO y contenidos de menor calidad.
Pese a que la intención original de Google es atacar el llamado «webspam», la ambiguedad de algunos criterios (ej: nadie sabe con exactitud a partir de cuando se produce un uso excesivo de palabras claves en un texto) puede provocar que muchas webs se vean afectadas en su posicionamiento en el buscador y en consecuencia en su número de usuarios (se recomienda estar atentos a través de herramientas como Google Analytics a una posible pérdida de trafico en los últimos días).
Al igual que pasara con la llegada de Google Panda, el nuevo Google Pingüino no ha sido bien recibido por la comunidad de webmasters, profesionales SEO y desarrolladores/ diseñadores web, en este sentido encontramos algunos casos que apuntan una bajada de hasta el 50% del tráfico a partir del pasado 24 de abril.
Si nos encontramos en uno de estos casos es muy probable que Google nos haya enviado anteriormente un mensaje indicando que nuestra actividad es considerada como webspam (Revisar la cuenta de Google Webmaster). Obviamente el primer paso es eliminar cualquier cosa que pueda ser considerada como webspam según las directrices de calidad de Google.
Además todos aquellos que consideren que se han visto afectados por el nuevo Google Pinguino tienen a su disposición un formulario donde dar detalles a Google acerca de porqué hemos sido penalizados de forma equivocada (Es conviente no usar el formulario para mostrar nuestra indignación sino dar argumentos que nos ayuden a recuperar nuestro posicionamiento). Este mismo formulario puede ser usado para señalar a Google aquellos contenidos que a nuestro juicio son considerados como webspam.
fuente.desarrolloweb
Google Panda, El Algoritmo que Penaliza los Enlaces NO-Naturales
Hubo un tiempo en el que la estrategia de conseguir enlaces entrantes de otras páginas web (Link Building) era una de las partes más sencillas y productivas de toda acción SEO. Esta situación era posible porque los artículos que incluían dichos enlaces no estaban dirigidos a ser leidos por las personas sino a indicarle al buscador acerca de nuestra relevancia.
No obstante lo anterior, tras la llegada del algoritmo de Panda a Google y la penalización de todos aquellos contenidos considerados como de menor calidad, se ha puesto de relieve los peligros de determinado tipos de tácticas en una estrategia SEO.
En este sentido son muchos los webmasters que en el último año han comenzado a recibir alertas de Google por enlaces sospechosos de no ser naturales y que por
apartarse de las guías de buena conducta que todo webmasters debe seguir (tratando de manipular su PageRank) podrían generar la correspondiente sanción en el posicionamiento de su website/blog.
Sites advertidos pero no penalizados:
Pese a que no todos los sites que han sido advertidos han recibido la ccorrespondiente penalización, el mensaje es claro, Google conoce el uso de estás tácticas y se reserva la opción de tomar medidas.
Es por ello que se hace necesario identificar los enlaces en cuestión y eliminarlos con utilidades como Open Site Explorer y las herramientas para desarrolladores de Google.
Además existen ciertas pautas que nos ayudarán a entender los criterios seguidos por Google a la hora de identificar artículos con enlaces no naturales:
-Temas sin conexión con el resto de contenidos del site
-Falta de sección acerca de, identificación del autor o medios de contacto
-Importantes cantidad de identicos anchor text apuntando al mismo site
-Artículos de 400-500 páginas con 2-3 links dirigidos a la misma dirección
Sites advertidos y penalizados:
Para aquellos que hayan sido penalizados hay una forma de volver a caer en gracia con Google pero esta ni es inmmediata ni probablamente nos permita recuperar nuestro estatus si éste estaba basado en enlaces de pago o redes de vínculos.
Una vez que hemos sido advertidos y castigados, necesariamente hay que sacrificar TODOS los enlaces de pago, presentar una solicitud de reconsideración y desarrollar una cartera de vínculos legítimos. Si la eliminación de los enlaces no naturales no es completa, la solicitud de reconsideración será denegada.
Además, aquellos sites penalizados que presenten la correspondiente solicitud de reconsideración deben ser honestos en sus alegaciones, mostrar su cambio de estrategia y demás rectificaciones que acrediten el cumplimiento de las guías de buena conducta de Google (Google guideline).
Pese a que la idea perseguida con esta firme posición de Google es la de penalizar todos aquellos contenidos considerados de baja calidad, así como las técnicas no naturales para adulterar lo que es considerado como relevante, una duda puede preocupar a aquellos webmasters y responsables SEO que solo usan técnicas legitmimas, ¿no podría usar esta técnica nuestra competencia para dañarnos?
La respuesta a la anterior pregunta es clara: SI. No obstante y dejando de lado temas éticos, el esfuerzo por provocar una penalización en nuestros competidores es casi tan grande como la de llevar a cabo una correcta estrategía SEO, mientras que los frutos de uno y otro trabajo poco tienen que ver.
fuente.desarrolloweb
Que es Google Panda?
Google Panda es un cambio en el algoritmo de Google ranking de resultados de búsqueda que fue lanzado por primera vez en febrero de 2011.
El cambio de objetivo de reducir el rango de «baja calidad sitios», y el retorno de más alta calidad sitios en la parte superior de los resultados de búsqueda. CNET reportó un aumento en el ranking de sitios web de noticias y sitios de redes sociales, y una caída en el ranking de sitios que contienen grandes cantidades de publicidad.
Este cambio habría perjudicado la clasificación de casi el 12 por ciento de todos los resultados de búsqueda. Poco después del lanzamiento de Panda, muchos sitios web, incluidos los webmasters de Google foro, se llenó de quejas de los raspadores / copyright infractores conseguir un mejor posicionamiento de los sitios con contenido original.
En un momento, Google pidió públicamente los puntos de datos para ayudar a detectar mejor raspadores. Panda de Google ha recibido varias actualizaciones desde el lanzamiento original, en febrero de 2011, y el efecto se hizo global en abril de 2011. Para ayudar a los editores afectados, Google publicó un aviso en su blog, dando así un sentido de auto-evaluación de la calidad de un sitio web.
fuente_wikipedia
What is Google Panda?
Google Panda is a change to the Google’s search results ranking algorithm that was first released in February 2011 .
The change aimed to lower the rank of «low-quality sites», and return higher-quality sites near the top of the search results. CNET reported a surge in the rankings of news websites and social Networking sites, and a drop in rankings for sites containing large amounts of advertising. This change reportedly affected the rankings of almost 12 percent of all search results.
Soon after the Panda rollout, many websites, including Google’s webmaster forum, became filled with complaints of scrapers/copyright infringers getting better rankings than sites with original content.
At one point, Google publicly asked for data points to help detect scrapers better. Google’s Panda has received several updates since the original rollout in February 2011, and the effect went global in April 2011. To help affected publishers, Google published an advisory on its blog, thus giving some direction for self-evaluation of a website’s quality.
source_wikipedia
HISTORIA de los ALGORITMOS
El origen del término «algoritmo» se remonta al siglo IX y se le atribuye su invención al matemático árabe Abu Ja’far Muhammad ibn Musa al-Khwarizmi.
La palabra algoritmo se refería originalmente sólo a las reglas de la aritmética con números arábigos. Recién en el siglo XVIII se expandió su significado para abarcar en su definición a toda clase de procedimientos utilizados con el propósito de resolver problemas o realizar determinadas tareas.
El primer caso de una algoritmo escrito para una computadora se considera que son las notas escritas por Ada Byron en 1842 para el motor analítico de Charles Babbage.
Por esta razón, se considera a Ada Byron como la primera programadora de la historia. Sin embargo, dado que Babbage nunca terminó su motor analítico, el algoritmo jamás llegó a implementarse.
IMPLEMENTACIÓN DE ALGORITMOS
La implementación es el proceso que toma la especificación del algoritmo y la traduce
a una forma que pueda aplicarse a la solución del problema para el cual fue diseñado.
La implementación puede tomar formas muy diversas: podría significar la construcción
de un circuito eléctrico o de un dispositivo mecánico que cumpla con las condiciones
especificadas. Pero restrinjamos la definición al campo de la informática:
en este sentido, implementar significa traducir el algoritmo a un lenguaje que pueda
ser interpretado por un motor de ejecución.
Para el análisis y estudio de los algoritmos usualmente se utiliza una forma abstracta
de implementación, la cual no utiliza un lenguaje de programación específico, sino
que emplea formas de representar el algoritmo que luego pueden ser directamente
traducidas a un lenguaje en particular. Algunas de estas formas son los diagramas
de flujo, los diagramas de bloques y el seudo código. Este último es “casi”
un lenguaje imperativo, con la salvedad de que no toma en cuenta los tipos de datos
y, además, sus instrucciones pueden estar en idioma español o en cualquier otro,
ya que no serán interpretadas por ninguna computadora.
Un sencillo ejemplo de la implementación en seudo código de nuestro algoritmo
BuscarMaximo sería la siguiente:
Función BuscarMaximo(lista)
Mayor = lista(1)
Contador = 2
Mientras Contador ? longitud(lista) hacer
Si lista(Contador) > Mayor entonces
Mayor = lista(Contador)
Fin Si
Contador = Contador + 1Fin Mientras
Devolver Mayor
Fin Función
Eficiencia de los algoritmos
La especificación de un algoritmo puede incluir consideraciones sobre su eficiencia,
dado que una implementación incorrecta puede hacer que demore en ejecutarse
mucho más tiempo de lo aceptable. Para ello se utilizan notaciones que expresan la
complejidad de los algoritmos en función del volumen de datos a procesar (ver el
Capítulo 4 para mayor información). Una de estas notaciones es la denominada “la
gran O”, que indica la cantidad de veces que el algoritmo debe repetir su bloque
principal de instrucciones para hacer su trabajo.
El ciclo principal del algoritmo BuscarMaximo –explicado en la página 20– recorre
una vez toda la lista de n elementos para determinar cuál es el mayor. Su bloque
principal (el delimitado entre Mientras y Fin Mientras) se repite tantas veces como
elementos haya en la lista. Por lo tanto, se dice que su complejidad es O(n) o que
tiene complejidad lineal, ya que el tiempo que demora en ejecutarse el algoritmo
aumentará proporcionalmente a la cantidad de elementos que tenga la lista.
ESPECIFICACIÓN DE ALGORITMOS
Para cualquier proceso computacional, el algoritmo correspondiente debe estar rigurosamente definido, es decir, debe especificarse la forma en que se aplica a cada posible circunstancia que pueda surgir. Todos los casos deben estar contemplados, y el criterio que determina cada uno de ellos debe ser claro y computable.
En general, no existe un único algoritmo para cada problema que se quiere resolver.
Diferentes algoritmos pueden completar la misma tarea, requiriendo cada uno diferentes cantidades de tiempo, espacio o esfuerzo. Sin embargo, la especificación puede ser exactamente la misma para todos ellos.
Para especificar un algoritmo de forma tal que su implementación sea correcta –es decir, que haga exactamente lo que se espera de él– y que, a la vez, pueda implementarse con diferentes lenguajes o herramientas, un método consiste en definir sus entradas y salidas, con sus correspondientes precondiciones y poscondiciones.
A modo de ejemplo, veamos la especificación de un algoritmo que busca el máximo
número en una lista:
Algoritmo: BuscarMaximo
• Datos de entrada: una lista l de n elementos numéricos.
• Datos de salida: un número m.
• Precondiciones:
n es un número natural.
n es mayor que cero (o sea, la lista no puede estar vacía).
todos los elementos de l son números racionales.
• Poscondiciones:
m es un número racional.
m es el mayor de los elementos de l.
Esta especificación define de manera inequívoca cómo debe funcionar nuestro algoritmo. Sin embargo, por estar expresado en lenguaje natural –con toda su carga de ambigüedades–, puede prestarse a confusiones (quizá no en este caso, porque es un algoritmo muy simple, pero sí para casos más complejos). Por ese motivo, conviene expresar las especificaciones en un lenguaje más riguroso, como por ejemplo, las expresiones matemáticas usadas en el cálculo de predicados lógicos. Con tales consideraciones, podemos expresar nuestro algoritmo en forma más precisa:
Algoritmo: BuscarMaximo
• Datos de entrada: l1 … ln
• Datos de salida: m
• Precondiciones:
n ? N
n > 0
li ? Q ? 1 ? i ? n
• Poscondiciones:
m ? Q
m ? li ? 1 ? i ? n
No cabe duda de que esta especificación es más rigurosa, aunque seguramente es más
difícil de entender para quien no domina esta clase de expresiones matemáticas.
En el Capítulo 3 se analizan con mayor nivel de detalle las definiciones de precondiciones
y poscondiciones de algoritmos, aplicadas a la especificación de tipos
abstractos de datos (TADs).
¿QUÉ SON LOS ALGORITMOS?
Un algoritmo es un conjunto finito de instrucciones precisas que realizan una tarea,
la cual, dado un estado inicial, culminará por arrojar un estado final reconocible.
Esta definición asume que la ejecución del algoritmo concluye en algún momento,
dejando fuera los procedimientos que ejecutan permanentemente sin detenerse. Para
incluir a éstos en la definición, algunos autores prefieren obviar la condición de que
la ejecución concluya, con lo cual basta con que un procedimiento sea una secuencia
de pasos que puede ser ejecutada por una entidad para que se lo considere algoritmo.
En el caso que no haya un estado final reconocible, el éxito del algoritmo no
puede definirse como la culminación del proceso con un resultado significativo.
En cambio, se requiere una definición de éxito que contemple secuencias ilimitadas
de resultados, por ejemplo, un sistema de compresión/descompresión de
datos en tiempo real (como los utilizados en el manejo de voz sobre IP); en este
caso, el algoritmo no define por sí mismo la finalización del proceso, debiendo
seguir su funcionamiento mientras haya datos para procesar. El éxito del algoritmo
estará dado por el hecho de que los datos, una vez descomprimidos, sean
iguales que antes de comprimirse.
El concepto de algoritmo se ilustra frecuentemente comparándolo con una receta:
al igual que las recetas, los algoritmos habitualmente están formados por secuencias
de instrucciones que probablemente se repiten (iteran) o que requieren decisiones
(comparaciones lógicas) hasta que completan su tarea. Un algoritmo puede no ser
correcto, con lo cual, por más que sus pasos se lleven a cabo correctamente, el estado
final no será el esperado.
Normalmente, cuando un algoritmo está asociado con el procesamiento de información,
se leen datos de una fuente o dispositivo de entrada, se procesan y se emiten por
un dispositivo de salida, o bien se almacenan para su uso posterior. Los datos almacenados
se consideran parte del estado interno de la entidad que ejecuta el algoritmo.
Dado que un algoritmo es una lista precisa de pasos, el orden de ejecución será casi
siempre crítico para su funcionamiento. En general, se asume que las instrucciones
se enumeran explícitamente, y deben ejecutarse “desde arriba hacia abajo”, lo
cual se establece más formalmente según el concepto de flujo de control.
Esta forma de “pensar” el algoritmo asume las premisas del paradigma de programación
imperativa. Dicho paradigma es el más común, e intenta describir las tareas
en términos “mecánicos” y discretos. Los paradigmas de la programación funcional
y de la programación lógica describen el concepto de algoritmo en una forma ligeramente
diferente (en el Capítulo 2 se detallan los distintos tipos de paradigmas).
Hasta aquí hemos dado una definición ciertamente informal del concepto de algoritmo.
Para definirlo en forma matemáticamente precisa, Alan Mathison Turing
–famoso matemático inglés (1912-1954), cuyas contribuciones en el campo de la
matemática y de la teoría de la computación le han valido ser considerado uno de
los padres de la computación digital– ideó un dispositivo imaginario al que denominó
máquina de computación lógica (LCM, Logical Computing Machine), pero
que ha recibido en su honor el nombre de máquina de Turing. Lo que confiere a
este supuesto dispositivo su extraordinaria importancia es que es capaz de resolver
cualquier problema matemático, a condición de que el mismo haya sido reducido
a un algoritmo. Por este motivo, se considera que algoritmo es cualquier conjunto
de operaciones que pueda ser ejecutado por la máquina de Turing (o, lo que es lo
mismo, por un sistema Turing completo, tal como se explica más adelante).
La máquina de Turing
Una máquina de Turing es un autómata que se mueve sobre una secuencia lineal de
datos. En cada instante, la máquina puede leer un único dato de la secuencia (generalmente
un carácter) y realizar ciertas acciones en base a una tabla que tiene en cuenta
su estado actual (interno) y el último dato leído. Entre las acciones que puede realizar,
está la posibilidad de escribir nuevos datos en la secuencia, recorrer la secuencia en ambos
sentidos y cambiar de estado dentro de un conjunto finito de estados posibles.
Un sistema Turing completo es aquel que puede simular el comportamiento de
una máquina de Turing. Dejando de lado las limitaciones impuestas por la capacidad
de almacenamiento o la memoria, las computadoras actuales y los lenguajes de
programación de propósito general definen sistemas Turing completos.
Independientemente de su forma concreta, cualquier dispositivo que se comporte
como un sistema Turing completo puede en principio ejecutar cualquier cálculo
que realice cualquier computadora; lógicamente, esta afirmación no considera la
posible dificultad de escribir el programa correspondiente o el tiempo que pueda requerir
realizar el cálculo en cuestión.
Podemos consultar la sección de Servicios al lector para conocer los sitios en donde
obtener más información acerca de los sistemas Turing completos.